First glance at & hands-on Aleph Alpha, the German competitor of OpenAI:
Their stated strong points:
- Explainable & trustworthy AI
- Deployment On-premise / any cloud infrastructures / their own datacenter in Germany
- so this is the closest thing I can currently think of regarding actually usable “GPT-on-premise”
- GDPR compliant usage
- European AI value chain
Their most shiny feature to me is their support for multi-modality, meaning you can process text as well as images. Screenshot #1 shows their Playground: input image (yellow), input text (green), completion result (gray).
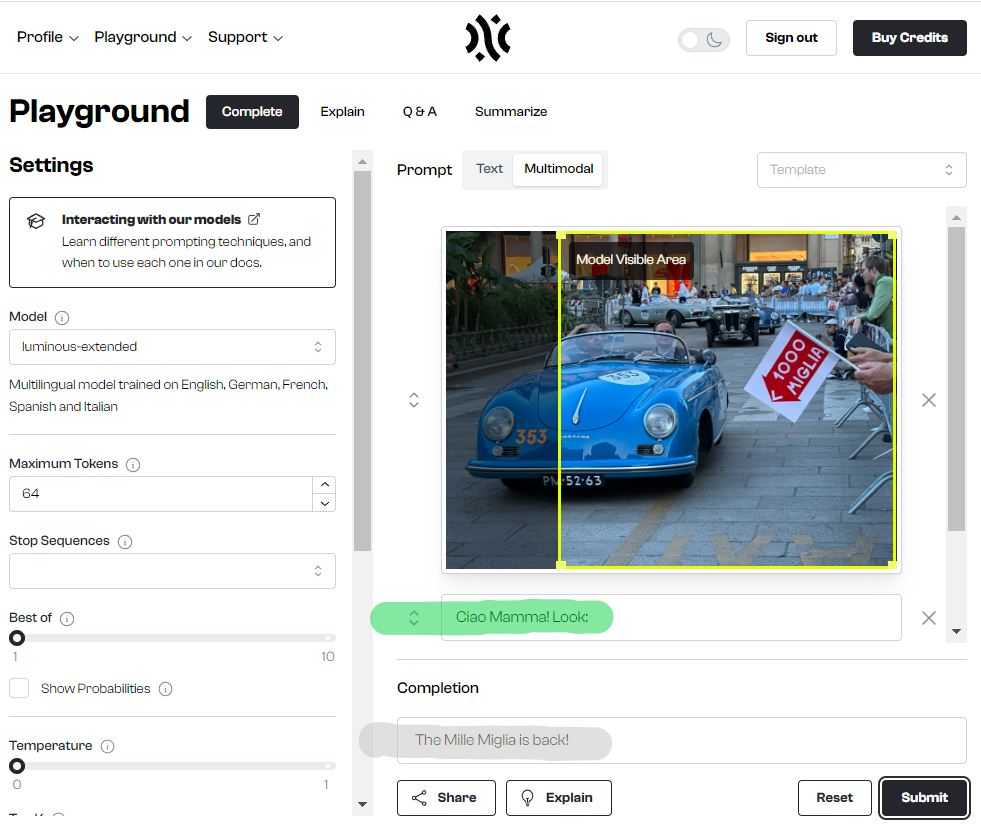
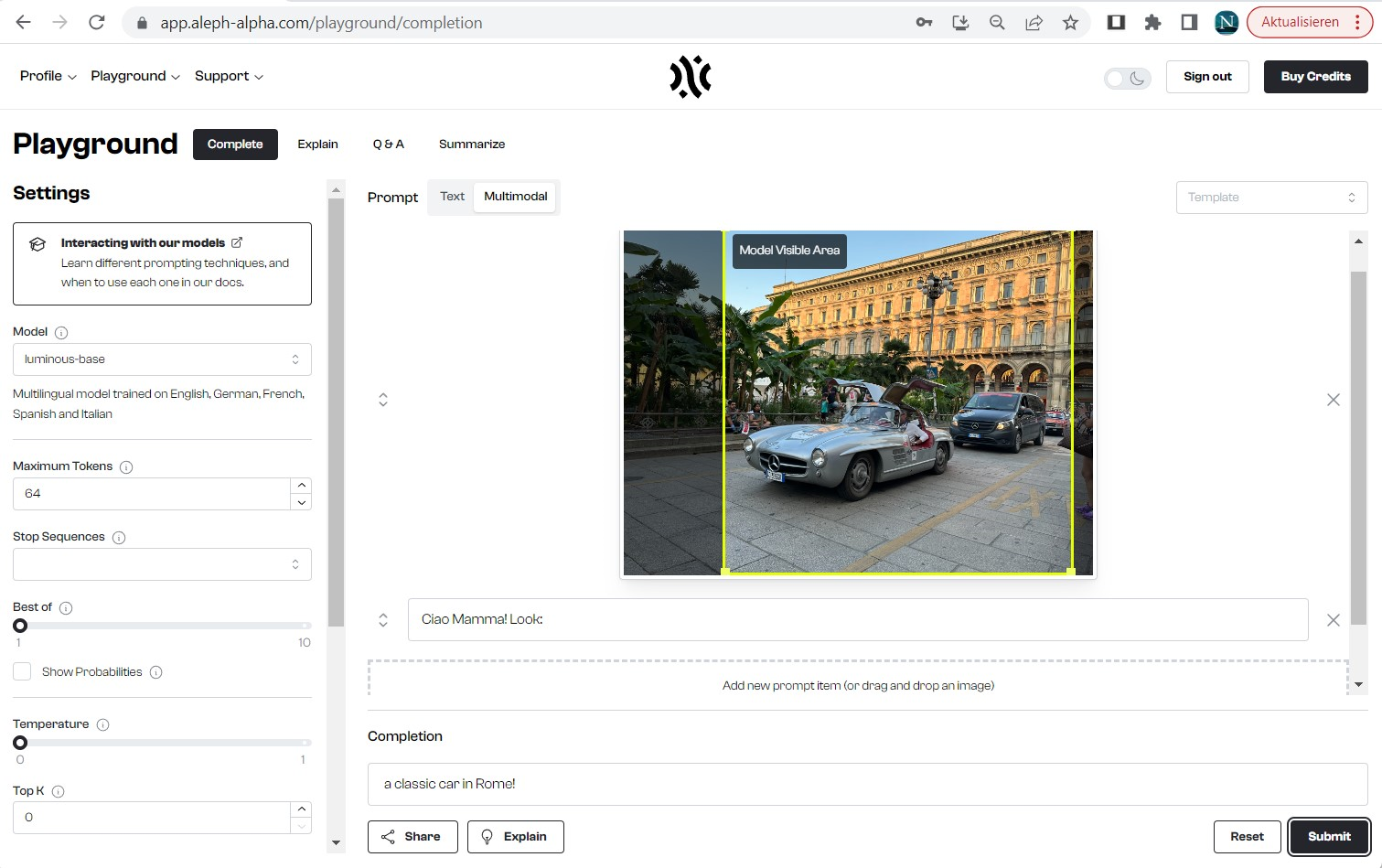
So I gave it a photo I took at the Duomo de Milano on Friday after AILab, started the text-completion with “Ciao Mamma! Look: “, and the model correctly completed the text with “Mille Miglia is back!”. Stellar first impression! 🤩 (when playing it a bit more with a wide-angle shot, it infers “Rome” (screenshot #2) - I’ll leave it to you guys to decide how bad a hallucination that is 😉)
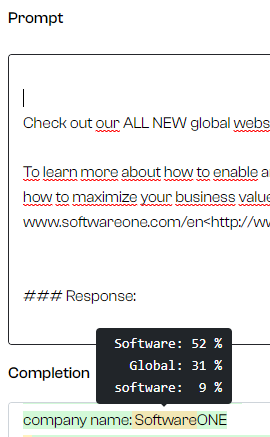
Another great feature is that you can get confidence values for segments (screenshot #3), which helps with detecting hallucinations - my working theory is that hallucinations/confabulations are actually low-confidence results. There is also an “Explain” function that highlights parts of the prompts that contributed to the result - and by how much (+/-).
In stark contrast to OpenAI, Aleph Alpha keeps prompts and results only in RAM, and discards them afterwards. OpenAI stores these for 30 days. This is set forth in the respective Terms & Conditions.
They have posted benchmark results that suggest similar performance to GPT-3. “Not quite”, I’d say at this point, but much more useful than the OpenSource/OpenScience B.S. that is frequently touted as “90% as good as GPT-3” or similar (problem being: 1) these models are at least fine-tuned on ShareGPT (and perhaps even TruthfulQA) and 2) GPT-4 is then used to grade responses 🤪). In my practical experience, it’s much harder to use that OpenAI GPT >= 3 (which they readily concede): e.g. my prompt engineering there involves A/B testing. 😕
Aside from “text completion”:
- they don’t have a dedicated chat fine-tuning/UI/API. You have to use their Instruct finetuned models (which they call “control”)
- “Q&A”, which allows upload of documents and pose questions (not tried)
- “Summarize” (also not tried)
- Embed/Semantic Embed
- the latter may address my concern that, based on experience with LlamaIndex, unrelated content may get lumped together/mixed up. But haven’t tried, either.
Other features:
- “AtMan” attention manager, which allows the user to guide the model’s focus to particular input segments, as if emphasizing something
- perhaps grounded in our shared European values & ethics, not American ones, as expressed in this Interview