The current state of Large Language Models, their costs and performance was discussed following up on Dr. Holger Schmidt, Editorial Editor at German newspaper FAZ, advertising an “AI Overview” article.
Cost-Performance Considerations
The discussion highlighted the complexity of comparing AI models based on cost-performance metrics. While the article presented a chart plotting various models’ quality index against their cost per million tokens, several important nuances emerged in the comments.
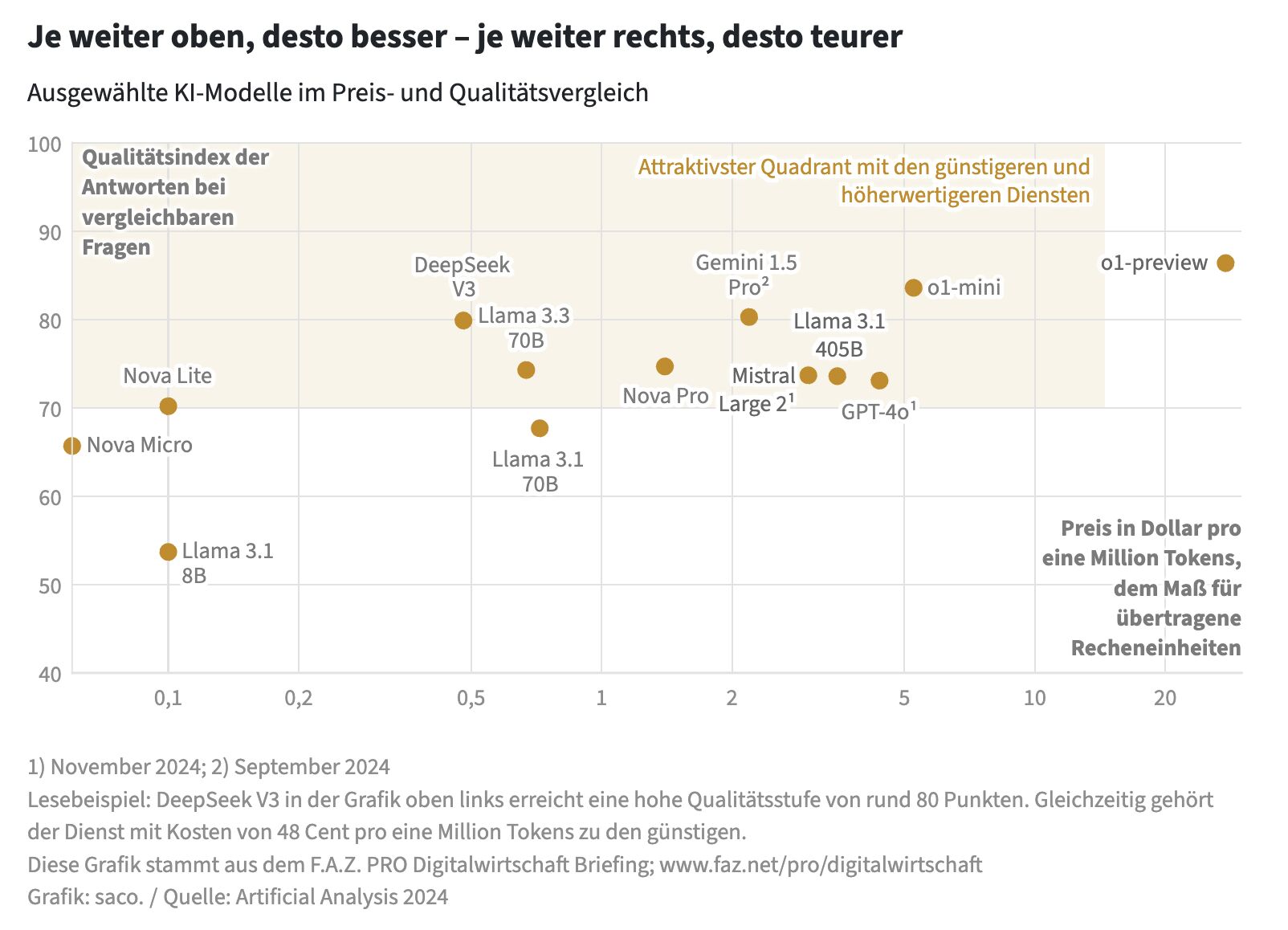
Mark Neufurth pointed out that the cost-per-performance unit could become a determining factor in AI deployment. He noted that models like Mistral and older versions of Llama appeared to perform well in this regard.
However, I cautioned against oversimplifying the cost analysis. The “token” as a base unit is not standardized across models, which can lead to misleading comparisons. This is particularly relevant when considering multilingual capabilities.
Language Support and Economic Viability
An important aspect that often gets overlooked is the varying support for different languages across AI models. I noted that some Chinese models, for instance, are primarily optimized for Chinese and English. This optimization can result in significantly higher costs when using these models for other European languages.
This observation led to a broader question about the economic viability of supporting languages beyond the major global languages at scale. However, there are reasons for cautious optimism:
- OpenAI’s release announcements suggest multilingualism as an optimization goal, mentioning languages like Gujarati in their GPT-4o announcement.
- A recent partnership between OpenAI and AI Singapore aims to promote language diversity.
- Research by Chang et al. (2022) shows that multilingual models encode some information (like token positions and parts of speech) along shared, language-neutral axes. This suggests potential for efficient cross-lingual learning.
While these developments are promising for language diversity in AI, challenges remain, particularly regarding regional specificities such as laws, norms, and values.
The Need for Custom Benchmarks
The rapid pace of AI development has led to a proliferation of benchmarks, many of which are academically focused or measure specific capabilities. However, these benchmarks often struggle to keep up with the latest developments or may not address practical concerns like quantization - a technique used by model providers to reduce costs at the expense of quality.
Given these limitations, I advocated for organizations to develop their own “evals” or benchmarks. These custom benchmarks need not be complex initially. For example, Simon Willison’s approach of having a language model draw “a pelican on a bicycle” provides a simple yet effective starting point. This method allows for gradual refinement based on specific requirements and use cases.
[Update 2025-01-06]: the FAZ benchmark used results from Artificial Analysis Quality Index. In this benchmark, GPT-4o mini ranks higher than GPT-4o - which says a lot about the quality of this “Quality” index, and underscores why own evals are worthwhile to create.