description: “Reflects on unexpected performance regressions in Claude 3, analyzing benchmark discrepancies, user frustrations, and potential regression causes.”
layout: post title: “Claude 2.1: Mysterious Disappointment” date: 2024-01-19 last_updated: 2024-01-19 tags: [Anthropic, Claude, Bedrock, Classification, RAG] —
This work is a gold mine: Mastering LLMs for Complex Classification Tasks. I expect the problems they describe to generalize beyond classification tasks (and has an immediate impact on advanced RAG pipelines). They conclude that:
The Claudes have been a somewhat mysterious disappointment, both in their extreme sensitivity to the prompt structure, as well as in non-EN performance. Anecdotally, these are fine models with great potential and we suspect they need more love and special care, i.e. bespoke prompting techniques, to coax best performance out of them.
Indeed, the Anthropic Cookbook proposes a prompting style that is yet different from the ones they have examined. However, I have achieved better results with violating the Cookbook (in very limited testing), which in my mind underscores the extreme unreliability/inconsistency expressed in this chart:
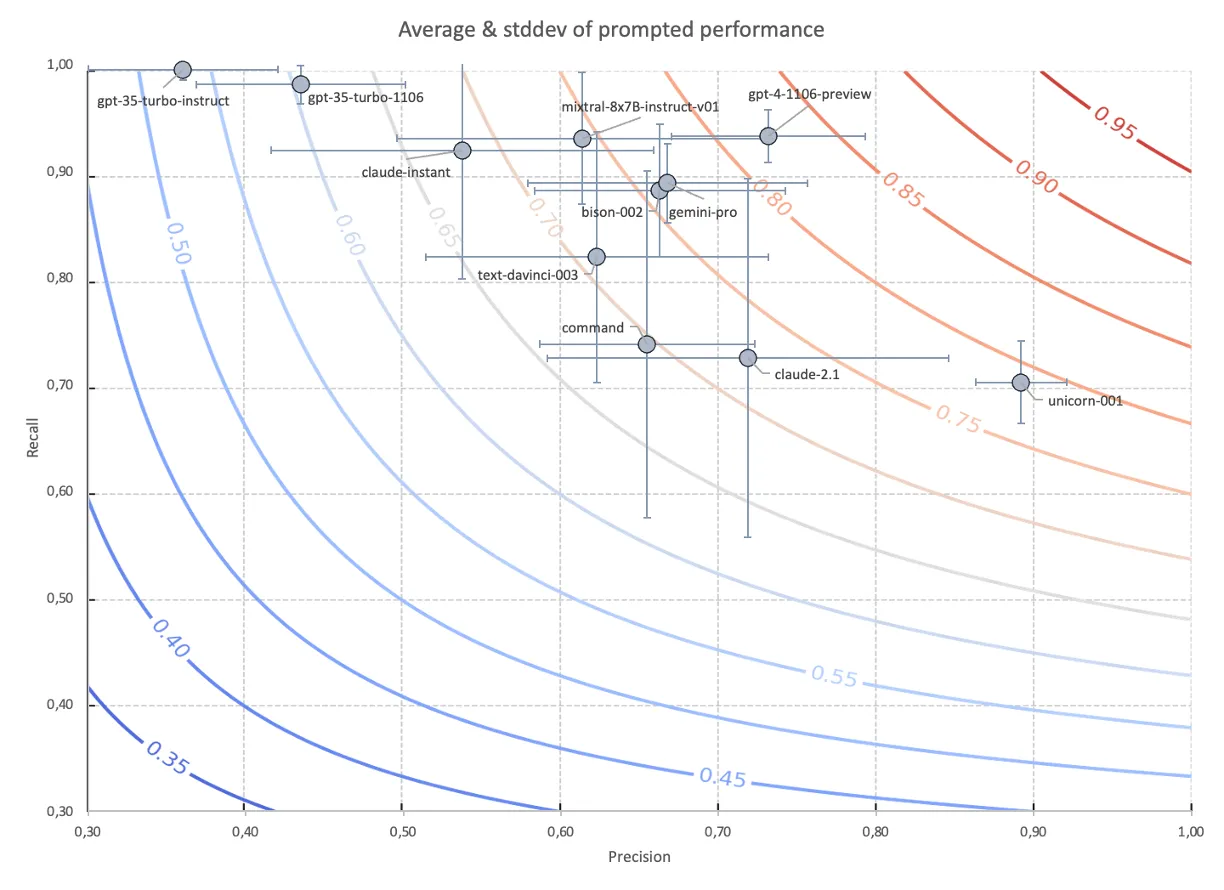
Because AWS Bedrock does not (to the best of my knowledge) let users differentiate between prompt and payload data, this spells trouble for any document processing and even simple RAG use-cases. (AWS have, IIRC, announced fine-tuning possibilites for Claude in the future. Maybe Claude can be fixed in the same way as GPT-3.5 can be fixed.)
Bottom line:
GPT-4 emerges as the top prompted performer setting a benchmark in the field, albeit with cost and latency considerations. GPT-3.5-turbo is great when fine-tuned, but serious questions about its baseline performance have surfaced. Google’s models, especially bison-002, show impressive performance at a favorable price point. Mixtral offers good performance at low cost.
They hint at another problem: support beyond English:
the performance drop on the non-English test set ranges from slight to dramatic, depending on the model. If multi-language is in the deck of your business requirements, this may be a strong constraint for choice of model and approach … which may be due to their testing approach: Note that languages were freely mixed, so an evidence/question pair may have Spanish evidence and a Dutch question — this is our business reality.
This matches my observation that staying within the same language improves performance. Money quote: “[for non-english content] Command and the Claudes implode”.