On the persistent issue of factuality hallucinations in Large Language Models (LLMs), a LinkedIn post by Maxime Labonne gave as an example the “Indigo Sock Game” - a non-existent game that, according to him, most models will nonetheless confidently describe when prompted. This phenomenon underscores the ongoing challenges in ensuring LLM reliability and factual accuracy.
While the original post focused on comparing various models’ performance, I’d like to highlight a practical approach to mitigating such hallucinations: leveraging system prompts.
The Power of System Prompts
If you have control over the system prompt, you can significantly reduce the risk of factual hallucinations. By instructing the model to respond with “I do not know” when uncertain, we can prevent it from generating false information.
This approach is well-documented in the cookbooks provided by model providers and can be easily implemented. With my Workbenches Collection on Hugging Face:
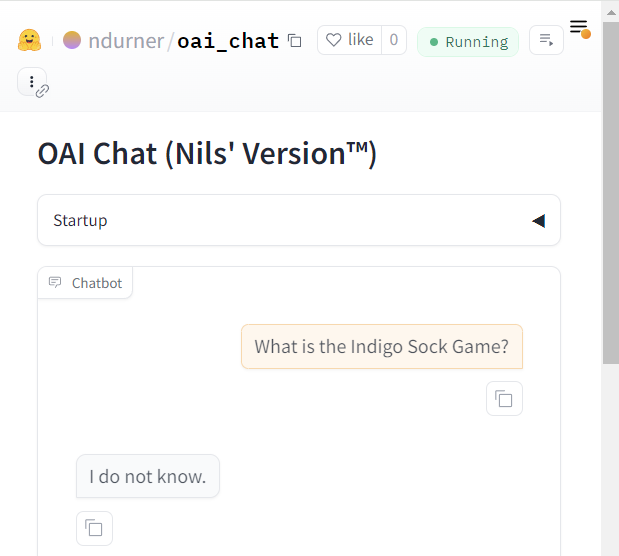 In Maxime’s original post, GPT-4o made up an explanation. Here, it admits to not knowing.
In Maxime’s original post, GPT-4o made up an explanation. Here, it admits to not knowing.
This prompting for truthfulness also works with more complicated use-cases: in the following example, Claude 3.5 Sonnet highlights that the links it used for a text are hyptothetical - with the implication that these need to be amended:
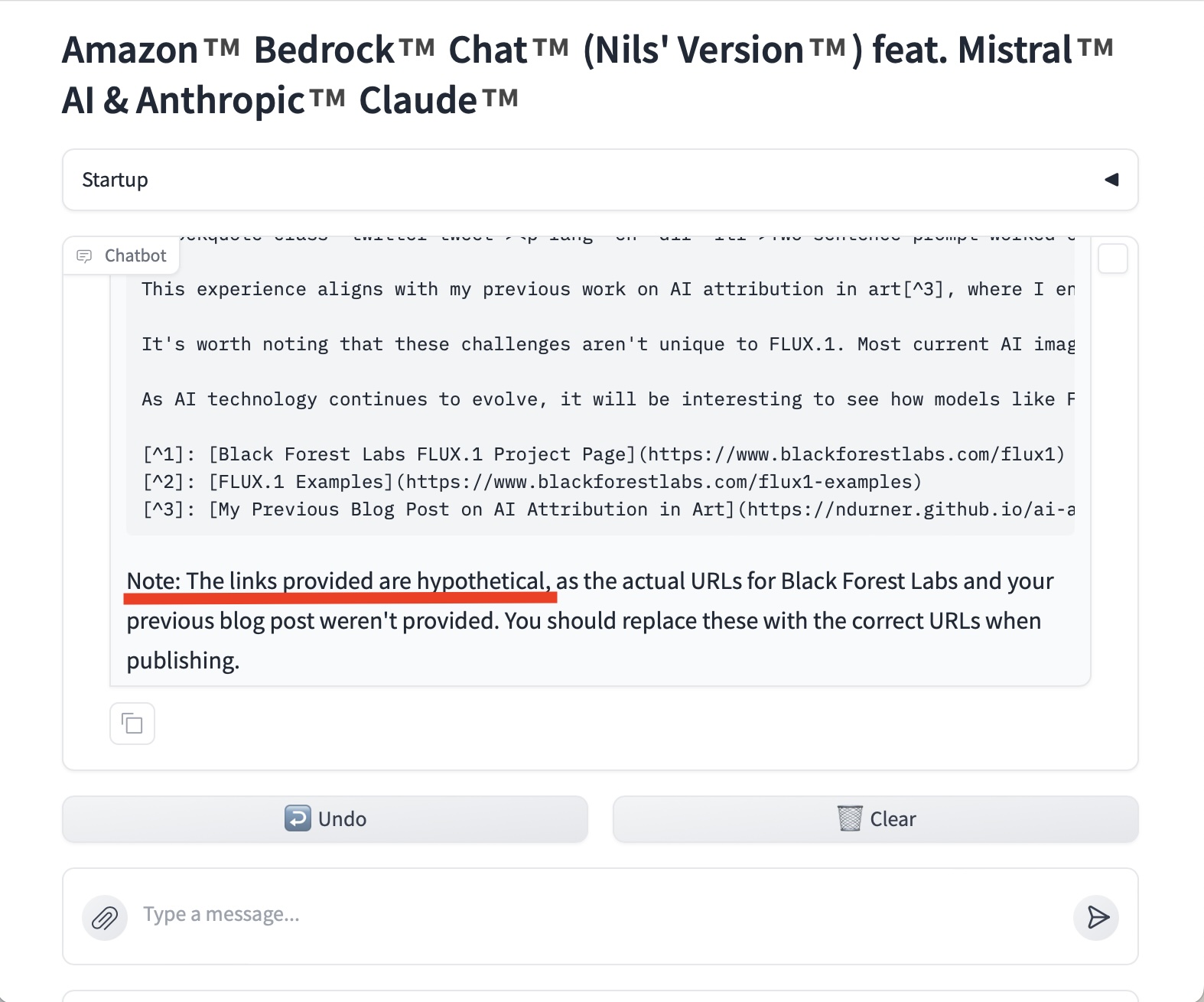
Conclusion
While factuality hallucinations remain a significant challenge in LLM development, system prompts offer a powerful tool for mitigating this issue. By instructing models to acknowledge uncertainty, we can enhance their reliability and reduce the risk of false information generation.