Mistral.AI 🇫🇷 have launched their Platform, which gives API access to their “best models” on a pay-per-use basis. Currently available on an invite-only, early-access basis.
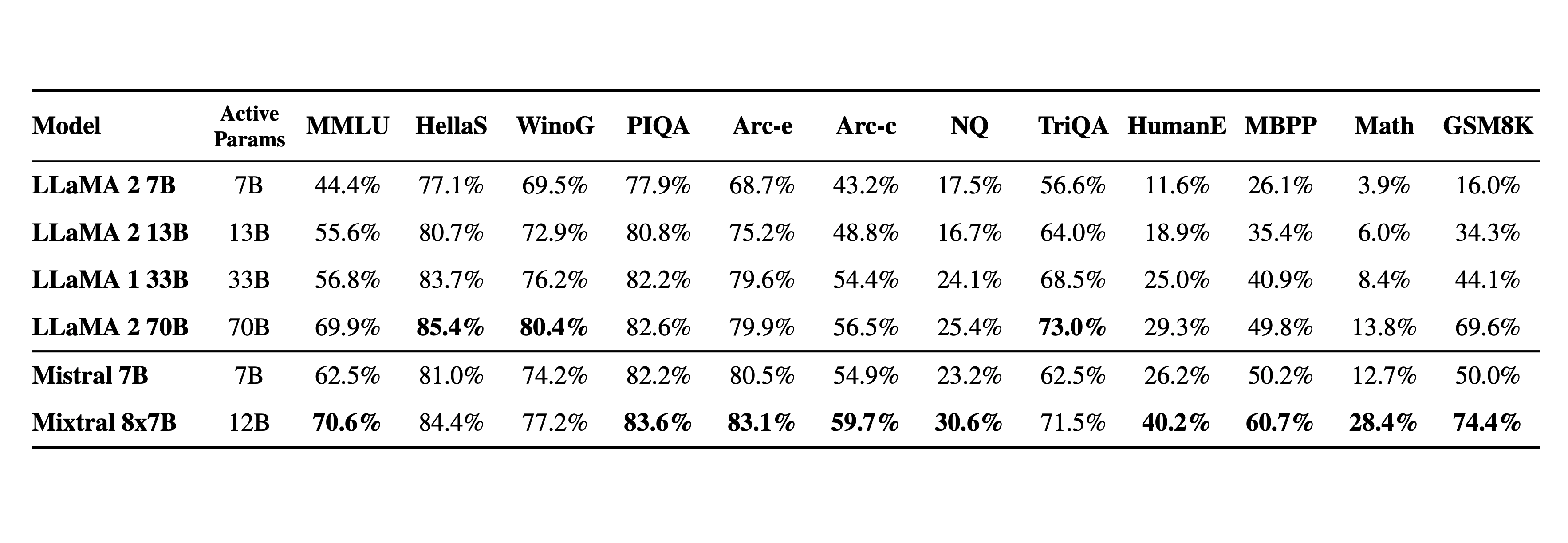
Background: Mistral have been in the news for making publicly available the weights etc. of rather small Text Generation models that show surprising performance in standard benchmarks compared to much larger, thus more resource hungry, thus much more expensive-to-operate, models (including Llama 2).
Different from what they call “Open Weights Models” which they have released for download prior, the Platform offers API access to three different models:
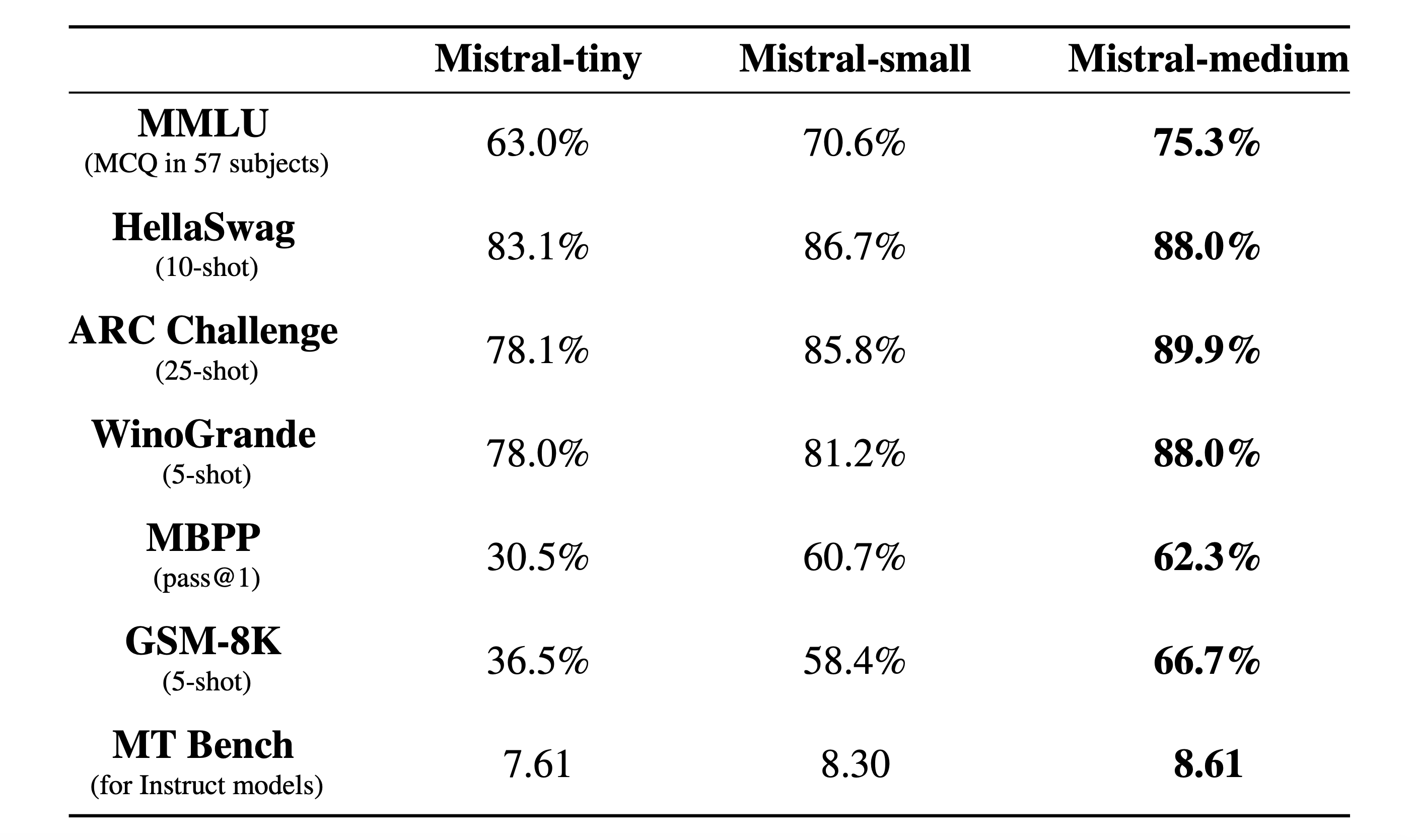
- Tiny: currently based on Mistral 7B (“Mistral-7B-v0.2”), “large batch processing tasks where cost is a significant factor but reasoning capabilities are not crucial.”
- Small: currently Mixtral-8X7B-v0.1, “supports 🇲🇫, 🇮🇹, 🇬🇧, 🇪🇸, 🇩🇪 and can produce and reason about code.”
- Medium: internal prototype model
All of these models are made available through a ChatCompletion-style API.
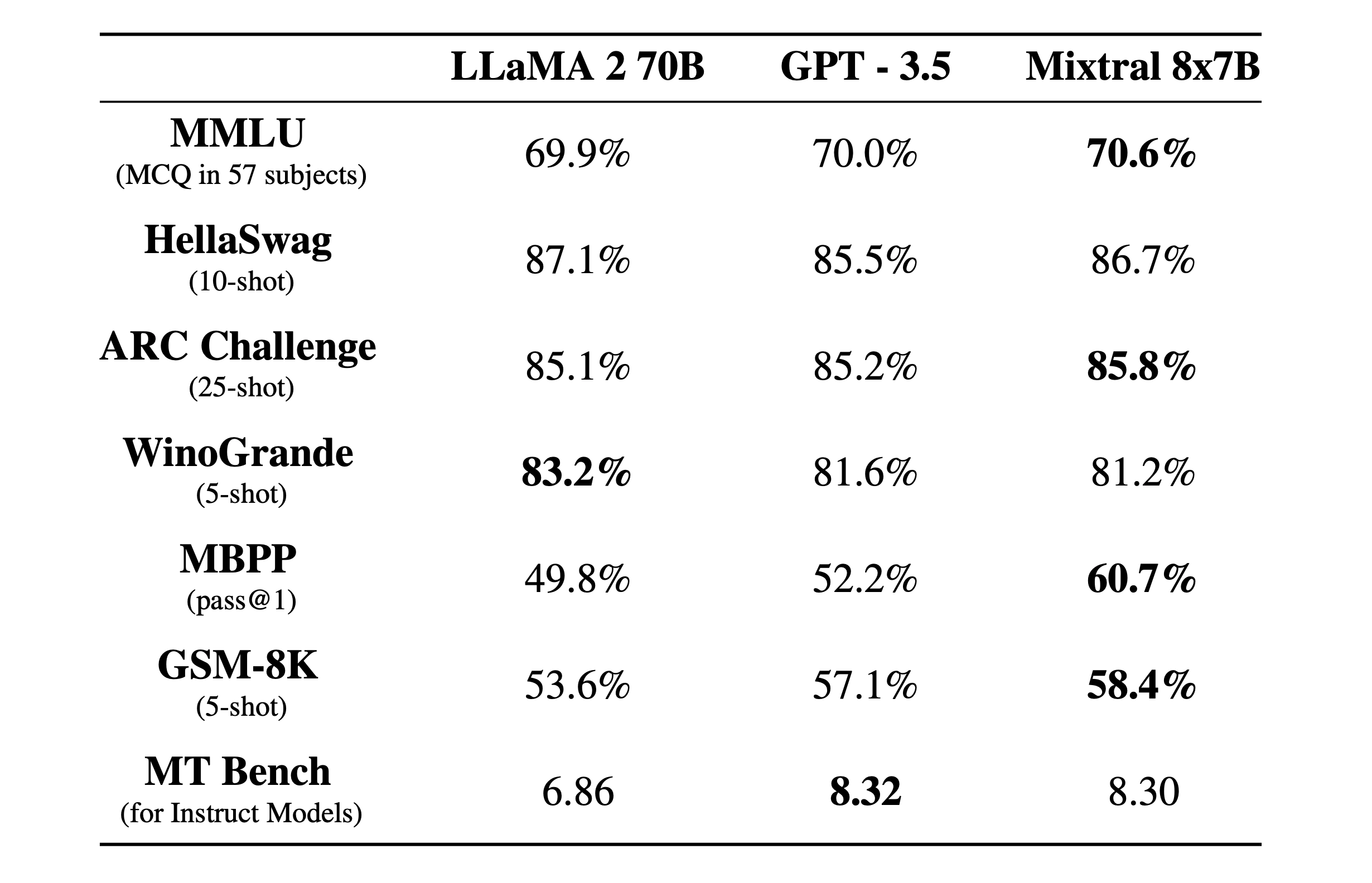
Based on the published results on standard benchmarks, Medium may outperform GPT-3.5 (screenshot #1-3), which is reflected by their pricing.
 \
\
The Platform website is rather bare-bones, with no Playground, Studio, or similar.
Costs: taking into account Tokenizer (in)efficiency, input of Italian language content to Mistral Medium may(!) roughly(!) cost:
- 0.33x of Claude-2 via AWS Bedrock, 0.31x of GPT-4 Turbo,
- 3.1x of GPT-3.5, 2.1x of AWS Titan Express, 1.53x of Llama 2 70B and 4x of Llama 2 13B (both via Bedrock)
Pricelist:
- Input: Tiny: 0.14€ / 1M tokens; Small: 0.6€ / 1M tokens; Medium: 2.5€ / 1M tokens
- Output: Tiny: 0.42€ / 1M tokens; Small: 1.8€ / 1M tokens; Medium: 7.5€ / 1M tokens
That’s good news for customers who require a purely European provider. Also note the continued breakneck speed: Llama 2 was released in July and now it -allegedly- is obsolete: “While being 6x faster, [Mistral Small] matches or outperforms Llama 2 70B on all benchmarks, speaks many languages, has natural coding abilities.” (at least for out-of-the-box use; perhaps the MoE architecture cannot be finetuned that easily?).