Anthropic have released Claude 2.1, with some commenters emphasizing
That new Anthropic pricing reflects a 20% discount to OpenAI’s most powerful models
… with Anthropic themselves highlighting a 200K context window and better accuracy with text summarization, among other things (Announcement).
Some context on this:
-
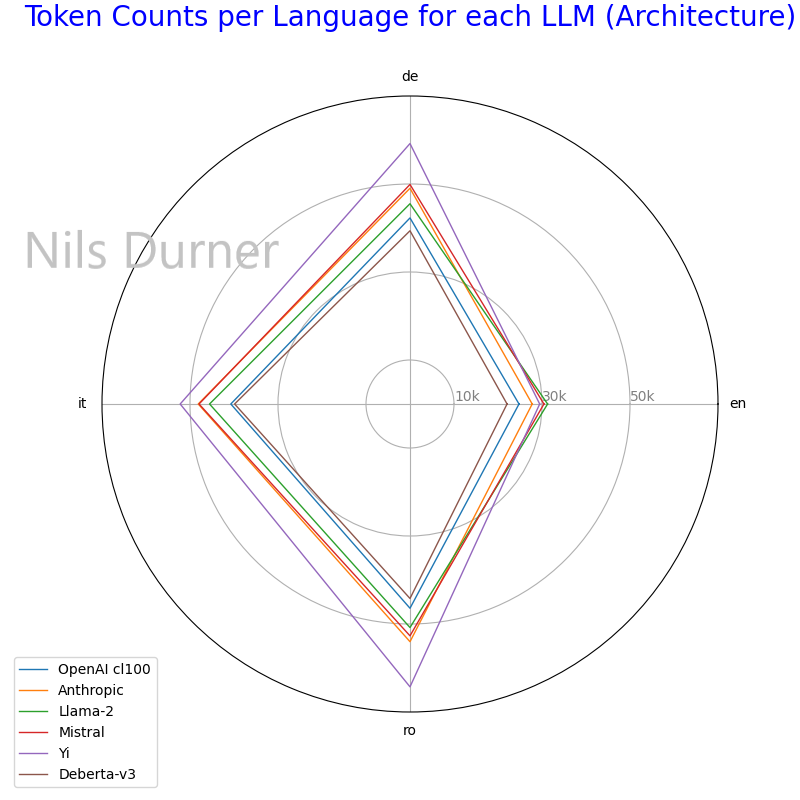
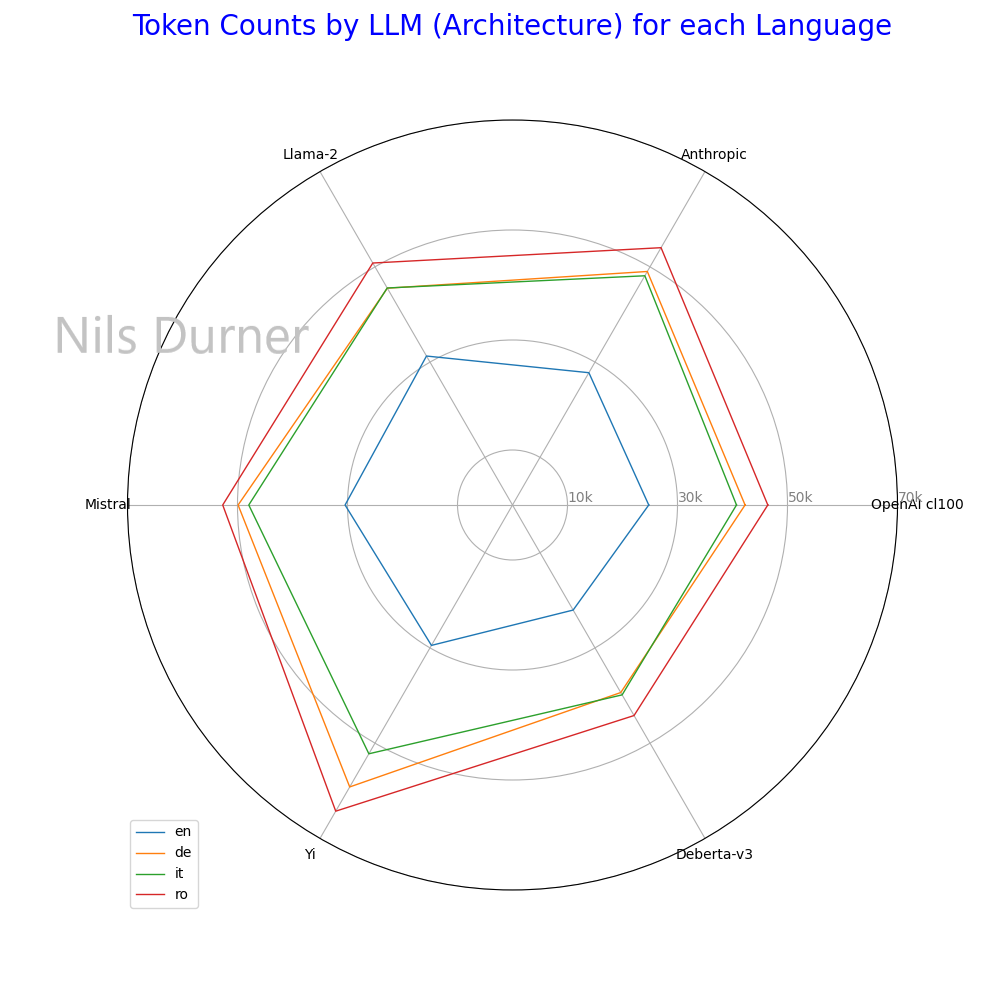
The Anthropic Tokenizer is less space-efficient than the one that is used for OpenAI GPT-3.5 Turbo and GPT-4 (“cl100k_base”). With the text content of “eIDAS 1.0” used as input, this relative inefficiency ranges from 12.12% (English language) to 18.17% (Italian Language). While the OpenAI Tokenizer is not unrivaled, it’s still one of the most-efficient allround - see charts #1 & #2 for comparison.
- Take this with a grain of salt: I quickly ran the numbers and didn’t really double check. Also, I only tested with de/en/it/ro natural language/legal text - outcomes may be different for different languages, with programming languages in particular.
- Yi by 01.AI just included to better establish the ballpark: as a bilingual English/Chinese model, other languages were obviously not an optimization goal.
-
This inefficiency means that the 100K Token context window of Claude 2.0 translates to, depending on the use-case, perhaps 84K in “OpenAI Tokens”. Conversely, the 128K context window size of GPT-4 Turbo would translate to 151K in “Anthropic Tokens”. The 200K for Claude 2.1 are undisputedly “more”, but not so much more as it may seem at first glance. Also, the alleged “discount OpenAI’s most powerful models” may actually cancel out.
-
What’s worse, attention over the context window is not just not-uniform (as discussed before), it’s like “Starting at ~90K tokens, performance of recall at the bottom of the document started to get increasingly worse” (chart #3, “Pressure testing Claude 2.1 200K via Needle in a Haystack” by Greg Kamradt). As one commenter pointed out, “recall at the bottom is basically 0%”. To be fair, the study has issues:
- I understood the authors are RAG believers, and their methodology mirrors that: they used some text “haystack” text and hid an entirely irrelevant “needle” text in there, with the needle being ““The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”. I think this is somewhat reasonable with RAG in mind, but not so much for other use-cases where ignoring irrelevant noise would actually be a neat feature. (Maybe this even is a feature? We can’t deny that for certain…)
- No human eval, GPT-4 was used as judge
-
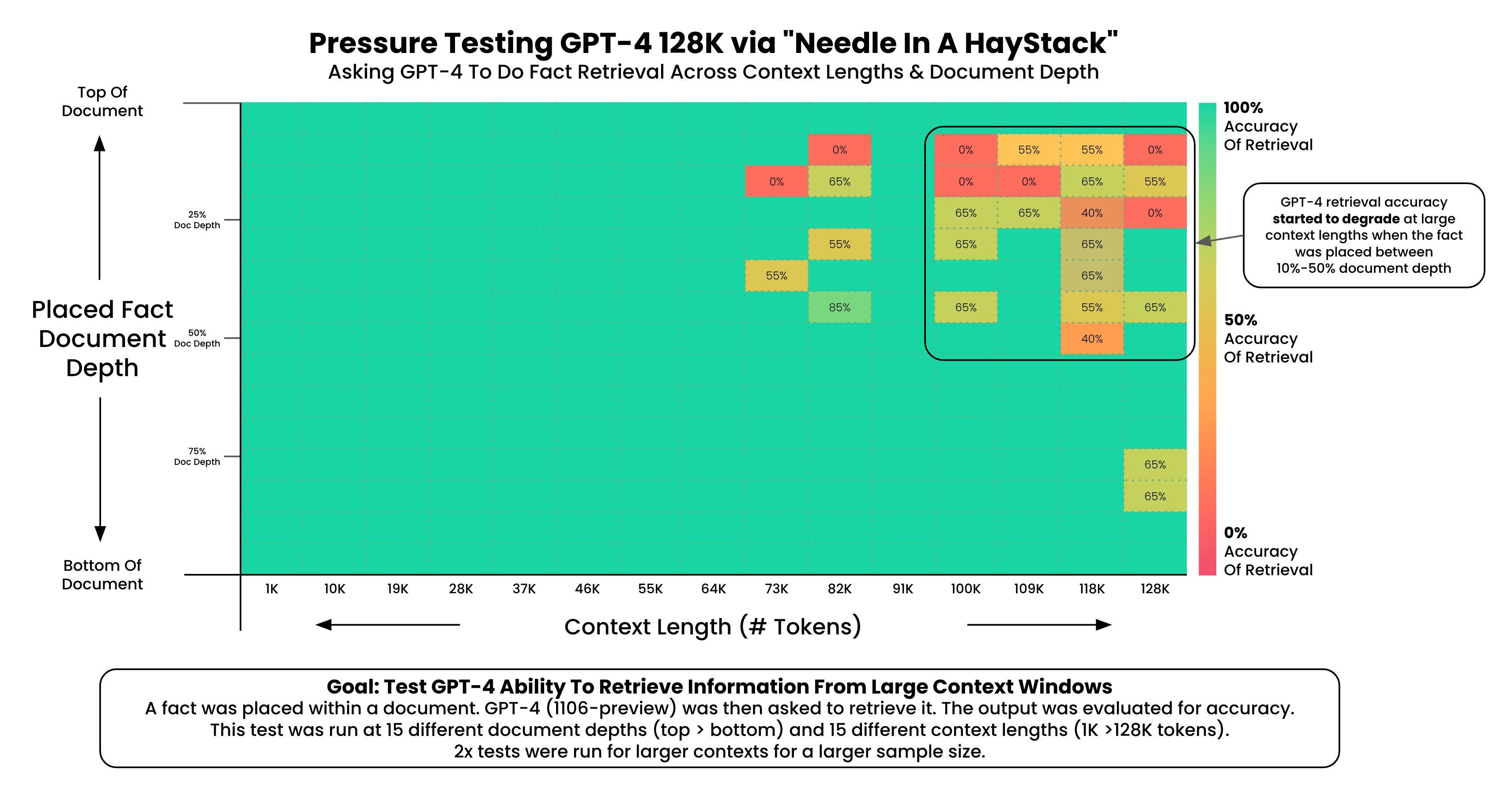
The same pressure test was also done on GPT-4 Turbo, with “GPT-4’s recall performance [only] started to degrade above 73K tokens” (chart #4).
In summary, only one thing is clear: the number of Tokens is the “Megapixels” of the 2020s: not necessarily a useful or even comparable unit of measure.