Google Gemini got launched (“our most capable AI model”).
Upfront summary: „Overall, you should probably keep using GPT-4/Bing for any complex tasks - it is still the best AI available“ (Ethan Mollick)
Literature:
Available through Bard immediately (although limited, and not in the EU) and through AI Studio and Vertex AI starting December 13.
Notes:
- comes in four sizes: Ultra (yet unreleased), Pro (used in Bard), and Nano-1 & -2
- tuned for Factuality: Attribution and the goal of not hallucinating. “Rather, it should acknowledge that it cannot provide a response by hedging”.
- Benchmarks suggest that Ultra will play in the same league as GPT-4/GPT-4V. Pro roughly seems to be GPT-3.5/Claude-2 grade, thus outperforming PaLM 2.
- (but they basically concur with Microsoft Research: “We believe there is a need for more robust and nuanced standardized evaluation benchmarks with no leaked data.”)
Bard:
- “For now, Bard with our specifically tuned version of Gemini Pro works for text-based prompts, with support for other content types coming soon.”
- will “come to more languages and places, like Europe, in the near future”
- “Gemini Ultra will come to Bard early next year in a new experience called Bard Advanced”
On the Technical Report:
- use-case examples in the Appendix, as well as in “5.2.5. Modality Combination”. Nice work! 👏🏻
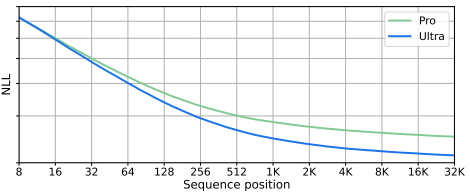
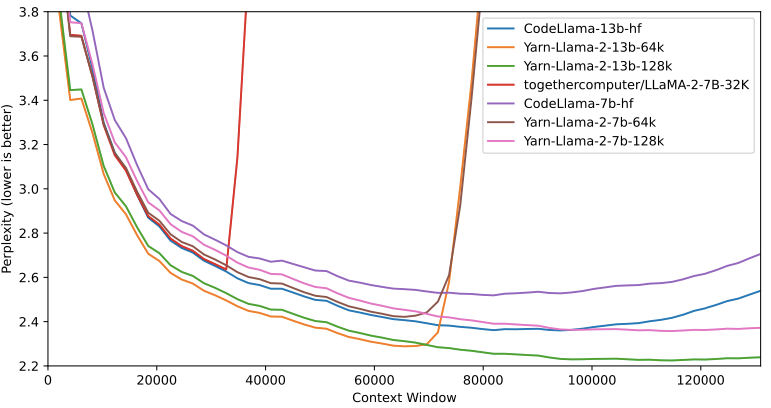
- it says that the 32K context window is used “efficiently”, with “98% accuracy when queried across the full context length”. However, I find the accompanying chart (image #1) a little lacking in meaning because it’s the models’ confidence (commonly also expressed as “Perplexity”, a metric derived from the NLL metric used here) and not the accuracy. The chart thus does not prove or illustrate the claim that precedes it 🤔 and just seems to say “it works” (chart #2 is an example of when things don’t work out that nicely; from the RoPE paper). Also, no statement is made about content shorter than 32K - which make a huge difference with both GPT-4 and Claude-2.
- Video content is actually ingested from several (key) frames, potentially with varying resolution. Similarly, the mention of “USM features” for audio seems remarkable.
- they note that “We have also observed that data quality is more important than quantity”, but confirm that “web documents, books, and code” were used.