Following up on my post about ChatGPT (not) getting dumber, a commenter remarked that Bard did better on this particular math excersise.
I offered the explanation that what they saw here with Bard is the use of a “tool” as proposed by Microsoft Research in their “Sparks of AGI” paper and recently made available by OpenAI:
- to developers in the form of GPT functions
- to end-users most visibly as part of ChatGPT Plus, in the form of Plugins
For reasoning about “Gen. AI”, it’s useful to differentiate between Models, Systems, Platforms and Use Cases, as proposed by Miles Brundage (Research Manager at OpenAI) in his talk “Where and when does the law fit into AI development and deployment?” at the Workshop on Generative AI and Law ‘23. Screencap:
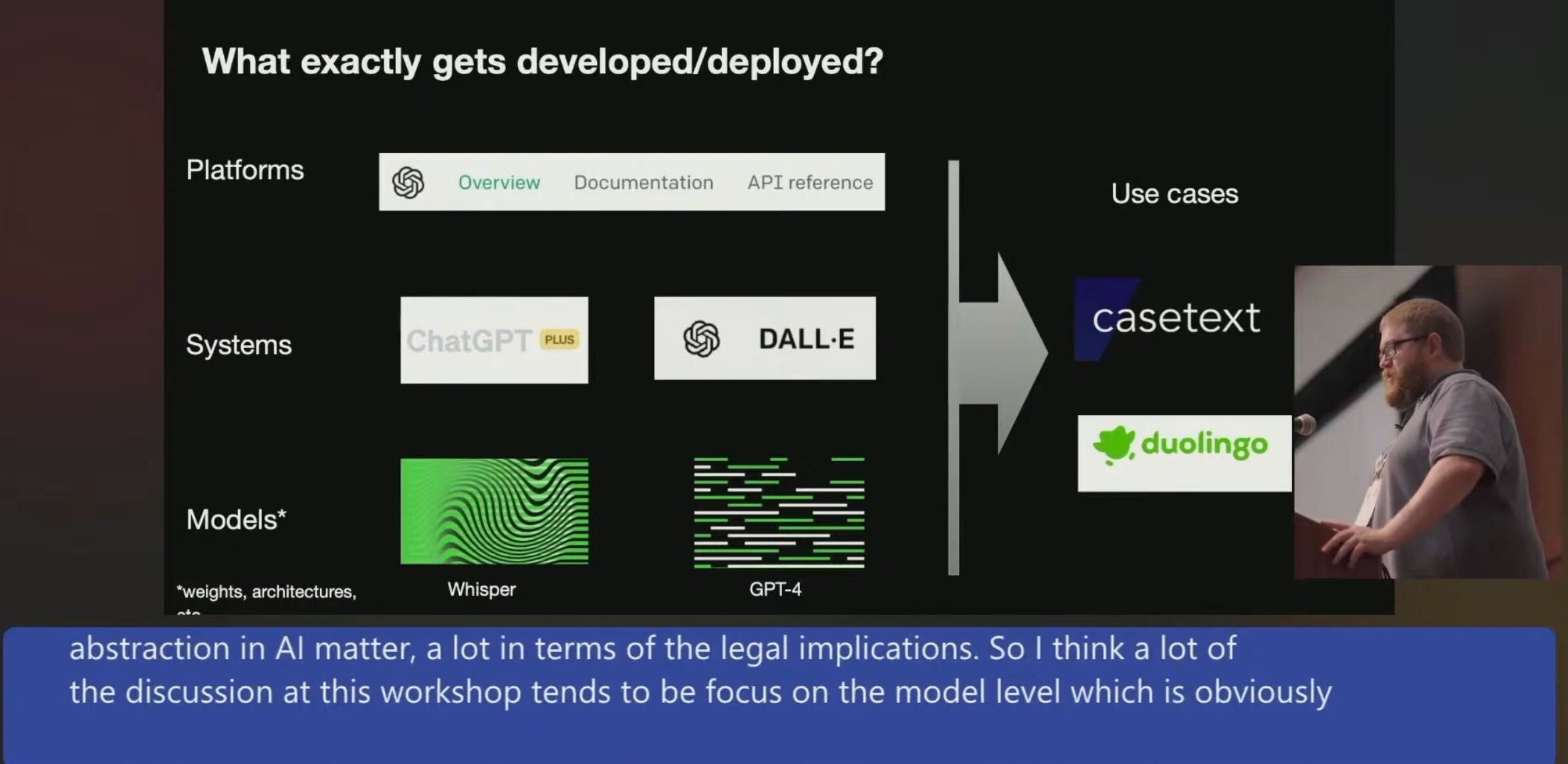
To connect this back:
- Zou et al. titled their paper “How Is ChatGPT’s Behavior Changing over Time?” 👈 this would be about a System (ChatGPT)
- What they supposedly really did, was to evaluate Models: “The LLM services monitored in this paper are GPT-4 and GPT-3.5, which form the backbone of ChatGPT. […] there are two major versions available for GPT-4 and GPT-3.5 through OpenAI’s API, one snapshotted in March 2023 and another in June 2023. Therefore we focus on the drifts between these two dates.”
- I could not reproduce the specific math error of 2647/7 with ChatGPT-on-GPT-3.5, the commenter could not reproduce it with Bard. 👉 so the Systems are made to work (at least sometimes/seemingly so?!), despite the Models not really being suited for this.
- Bard is a System, like ChatGPT. PaLM and PaLM 2 are Models, like GPT-4
- “Model” as used by Miles; the definition may be slightly different depending on whether a Model belongs to the Open or Proprietary category.
In summary, I would expect the same math errors that Zou et al falsely reported for ChatGPT to show with PaLM (like they do with gpt-3.5-turbo) but actually neither with ChatGPT nor Bard - because of their System nature.
This kind of considerations is relevant for us Builders because it highlights how the Models are really just one building block, behaviour observed with the Systems does not always apply to the Models (and vice versa), and for our downstream tasks (“Use Cases”, in Miles’ slide) we may have to duplicate certain functionality found in Systems like ChatGPT (Plus, in particular) or Bard. Also, other Use Cases (really: AI-powered third-party Apps) may establish certain expectations with users - that’s why feedback from downstream users and their use-cases to us upstream builders/users is vital. Keep it up! 👍
Reference to recent Bard improvements: Bard is getting better at […] math prompts
Bottom line: I really liked Miles’ talk. Highly recommended myth-busting material, even if you’re not really interested in Law-Making per se.