Reka AI has released a hand-curated dataset, benchmark and leaderboard to grade web search and answer generation of LLM systems. Their blog post describes “Research Eval” as Diverse (374 questions with grading guidelines, across a wide range of topics), Discriminative (current frontier models achieve between 26.7% and 59.1% accuracy), and High-quality (rigorously vetted, fixed, and filtered through a rigorous multi-step annotation process).
However, their selection of model performce reported appears partially outdated: Gemini 2.0 Flash, GPT-4o search preview. LLMs I recognize as current generation are Claude Sonnet 4 and Grok 4.
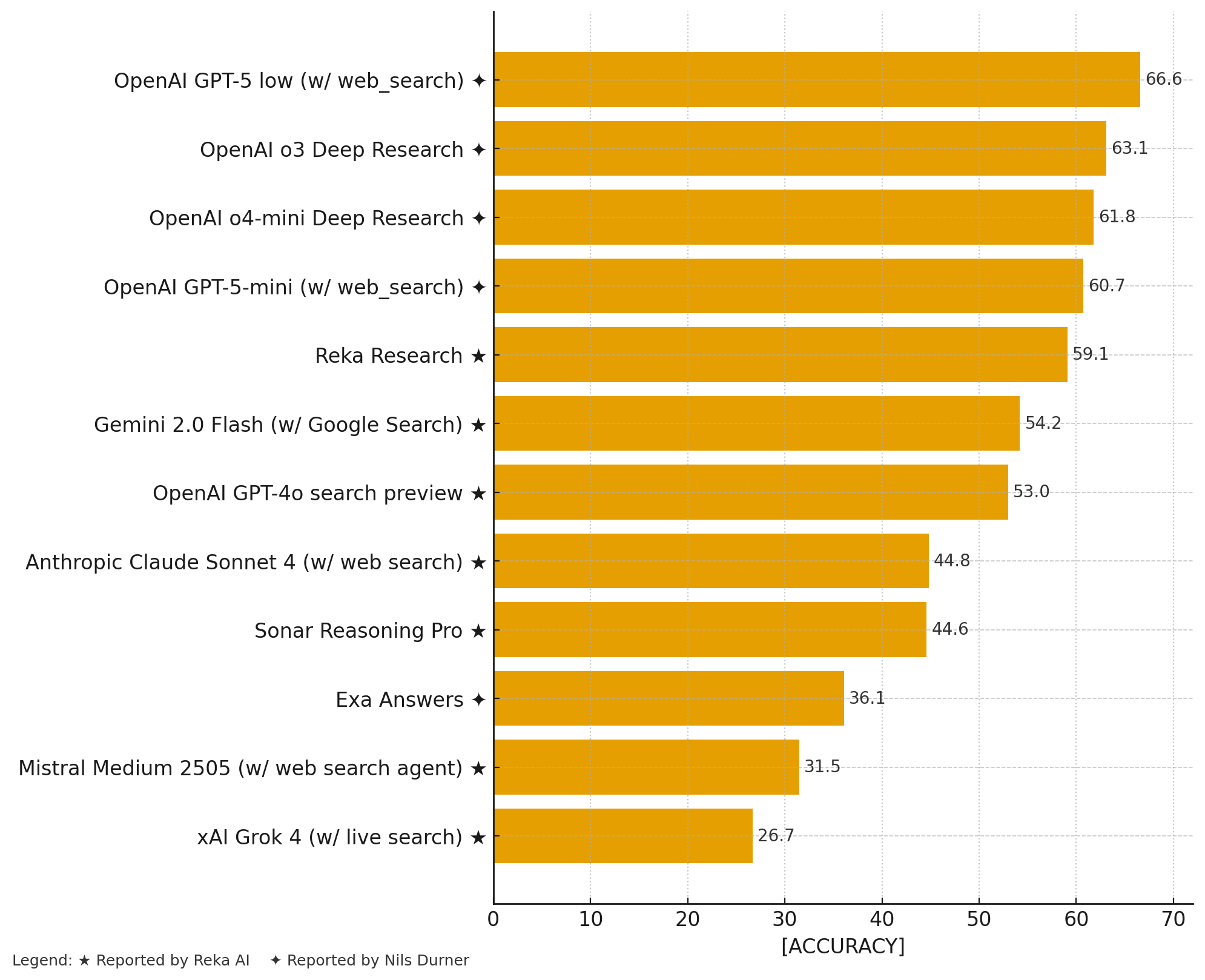
For the leaderboard to include some models and systems I am currently interested in, I have forked their repository at ndurner/web-research-eval and added support for the OpenAI Responses API and Exa Answers. The leaderboard now looks like this:
| Model | Accuracy |
|---|---|
| OpenAI GPT-5 low (w/ web_search) ✦ | 66.6 |
| OpenAI o3 Deep Research ✦ | 63.1 |
| OpenAI o4-mini Deep Research ✦ | 61.8 |
| OpenAI GPT-5-mini (w/ web_search) ✦ | 60.7 |
| Reka Research ★ | 59.1 |
| Gemini 2.0 Flash (w/ Google Search) ★ | 54.2 |
| OpenAI GPT-4o search preview ★ | 53.0 |
| Anthropic Claude Sonnet 4 (w/ web search) ★ | 44.8 |
| Sonar Reasoning Pro ★ | 44.6 |
| Exa Answers ✦ | 36.1 |
| Mistral Medium 2505 (w/ web search agent) ★ | 31.5 |
| xAI Grok 4 (w/ live search) ★ | 26.7 |
Legend
- ★ Reported by Reka AI
- ✦ Reported by Nils Durner
Because the Exa AI search index previously appeared to be more complete, I’d treat their result as a baseline for own integrations through the Exa Search API/MCP server. Or perhaps use their Research API.
Extended Leaderboard chart with my additions: