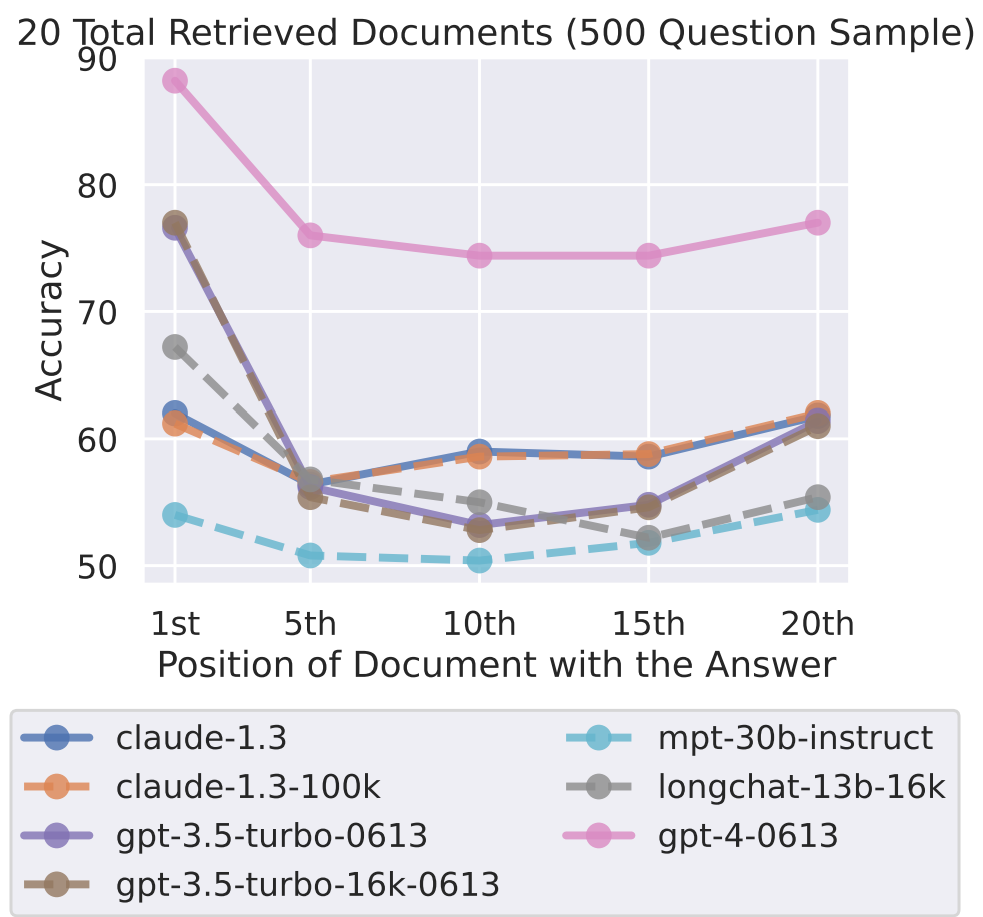
Non-uniform performance reported for in-context learning: How Language Models Use Long Contexts:
- Model performance is highest when relevant information occurs at the beginning or end of its input context
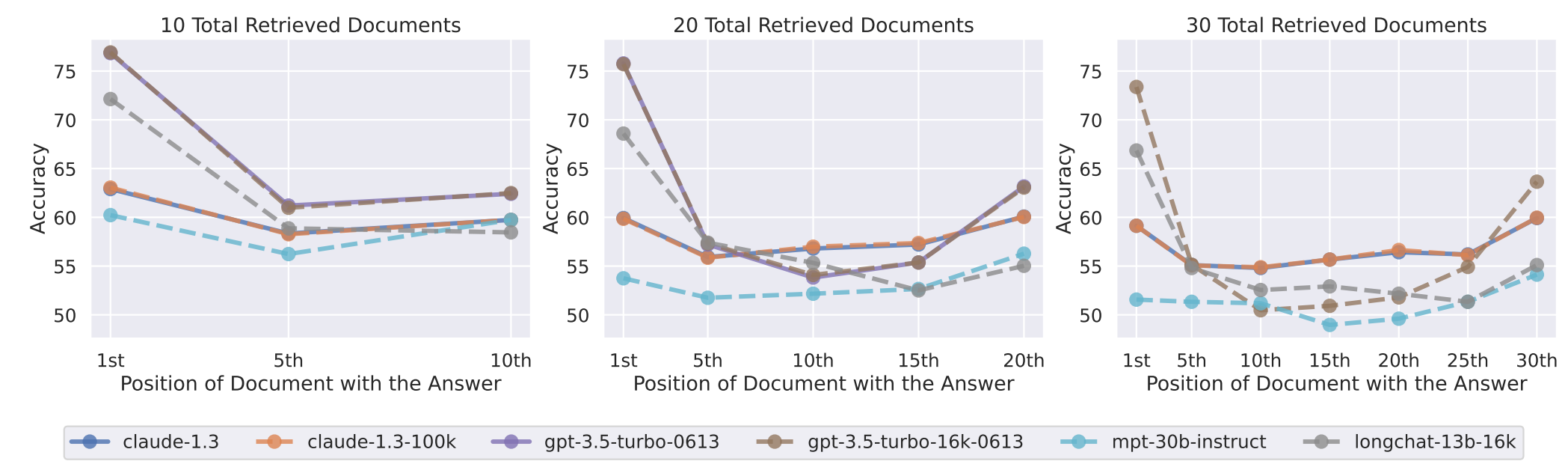
- Model performance substantially decreases as input contexts grow longer
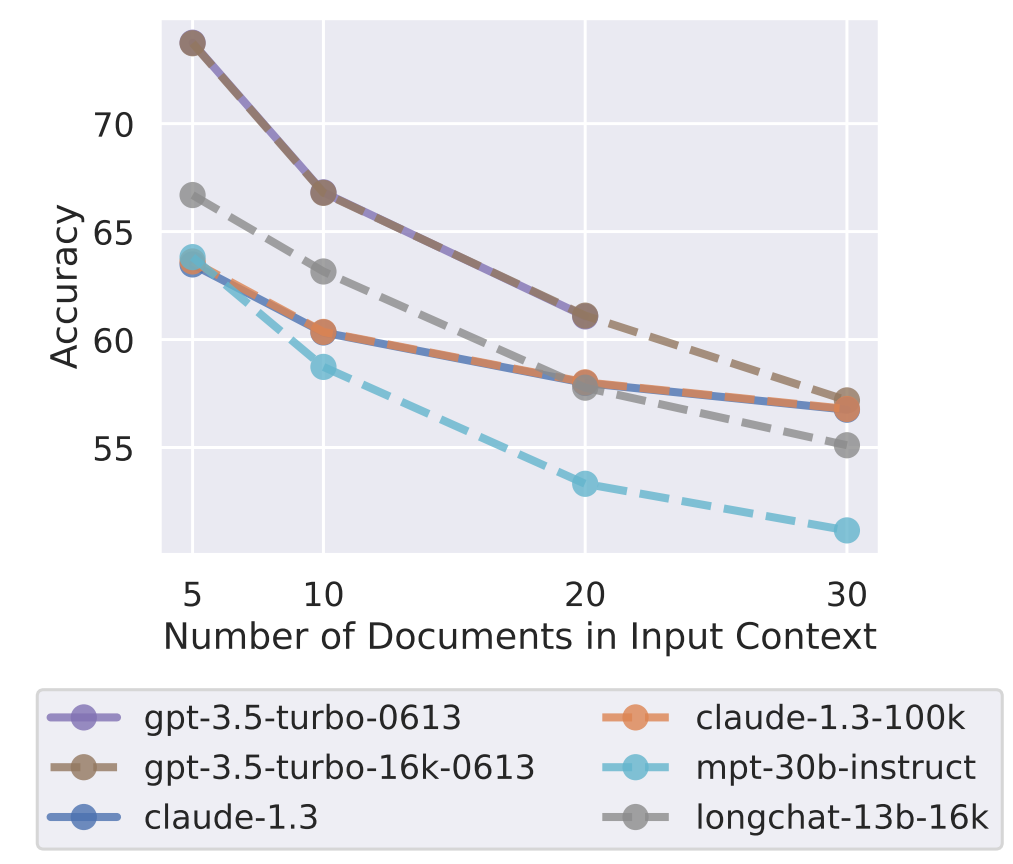
- Extended-context models are not necessarily better at using input context
The degradation effect itself is less pronounced with Claude. Their 100K model does not perform much differently than the default model, it seems.
Notably missing is GPT-4 (in the full overview; partial results in Annex C).
Prior research has concluded that fine-tuning hurts in-context learning abilities, but the authors of this paper reject this as an explanation:
Surprisingly, we see that both MPT-30B and MPT-30B-Instruct exhibit a U-shaped performance curve, where performance is highest when relevant information occurs at the very beginning or very end of the context. Although the absolute performance of MPT-30B-Instruct is uniformly higher than that of MPT-30B, their overall performance trends are quite similar.
Instead:
We hypothesize that language models learn to use these contexts from similarly-formatted data that may occur in webtext seen during pre-training, e.g., StackOverflow questions and answers.
These results cast further doubt on Retriever-Architectures like LlamaIndex:
effective reranking of retrieved documents (pushing relevant information closer to the start of the input context) or ranked list truncation (returning fewer documents when necessary; Arampatzis et al., 2009) may be promising directions for improving how language-model-based readers use retrieved context
Intriguing tidbit at the end:
The U-shaped curve we observe in this work has a connection in psychology known as the serialposition effect (Ebbinghaus, 1913; Murdock Jr, 1962), that states that in free-association recall of elements from a list, humans tend to best remember the first and last elements of the list. The serial-position effect plays a role in understanding how humans develop short- and long-term memory.
Footnote:
We also use the OpenAI API to evaluate GPT-4 on a subset of multi-document QA experiments, finding similar results and trends as other models (though with higher absolute performance). Evaluating GPT-4 on the full multi-document QA and key-value retrieval experiments would cost upwards of $6000